REMAIN COMPOSED :: KRISTINA WARREN :: FIELD NOTES :: PRODUCTION AND GROOVE :: GRANULATION A LA LOOPSLIDER (PART 2)
[box] For this special feature in our ongoing Field Notes series (where creators from all disciplines shine light behind the curtain at their daily practice — revealing the often messy, sometimes frustrating, surprisingly beautiful life along the way) the OS is excited to have composers Todd Lerew, Kristina Warren and Michael Laurello, finalists in the 2014 American Composers Forum National Composition Contest. Lerew, Warren, and Laurello have been sharing their process notes with us as they develop new work through July, when the pieces will premiere at the Sō Percussion Summer Institute at Princeton University. Get better introduced – and listen to samples from these innovative new composers — at our series introduction, HERE. We’ve had one round of entries from each composer so far — you can find links to each at the bottom of this article. GET INSPIRED. Take notes! [/box]
Hi, I’m Kristina Warren, back for a second post on my process of composing a piece for So Percussion. Like last time, my writing is fragmentary on purpose.
[line]
I realized recently, for this piece I got deep into the score right away.
I spent three months drafting the concept.
I spent three months figuring out how to make iDraw, a faux-Illustrator software which I use often, work in my favor.
Yet the score is always in service of the sound.
In computer music, “granulation” is playing tiny snippets of a source sound.
Synchronous granulation draws snippets from the source in a forward linear fashion.
Asynchronous granulation draws snippets from all over, all different parts of the source audio.
Recently I made a Max/MSP patch, called loopslider, that does both synchronous & asynchronous granulation.
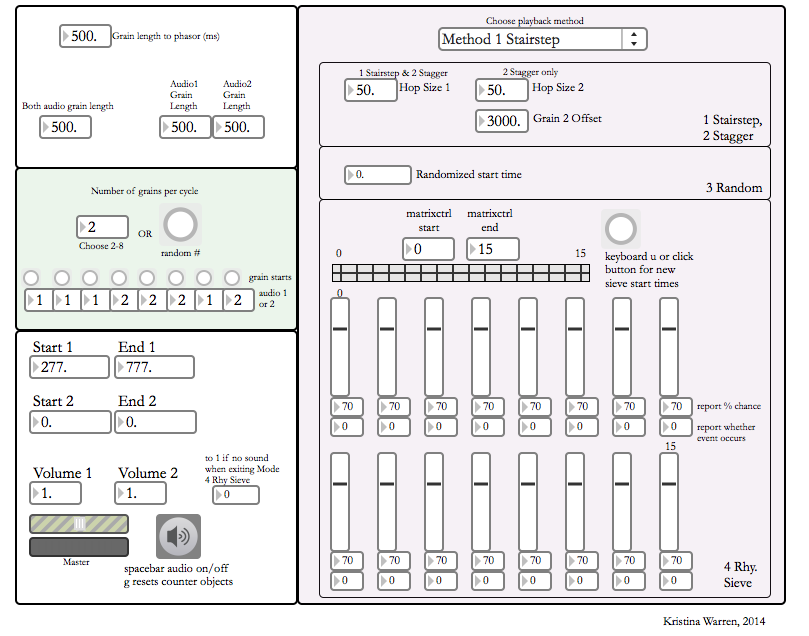
In the audio below, I’m using loopslider to move from synchronous granulation to a looped asynchronous texture.
All the voices are mine.
(It’s important to me that, unlike some producers, I produce only myself. (Is that right?))
There are two source audio files: my tape piece Up in the A.M., and myself reading the text below, which is from J.K. Randall’s 1985 article “Are You Serious?”.
[box]These images of love and beauty are what? They’re the sanitized prettypatty prefab our shit’s managed to cohabit with for quite some time now thank you, that’s what. Shoved at you lifedepth, over liferange, it puts the wrong bite on you. Just about tells you to look the other way, don’t work it thru. Almost says: since what’s wrong makes you feel so bad let’s grease your feelings. Almost tells lies about what’s out there, or in there. I’ll have to try this one out on Moses. Doesn’t clean out any new space in you for love and beauty. Just rings your chimes.[/box]
[line]
Audio Player
I realized recently, I’m kind of asking SP to granulate.
I didn’t mean for this acoustic piece to emulate my electronic music.
I meant to be non-hegemonic.
The best way I know to do that is to ask performers to make lots of choices.
Their choices guide how they’ll chop up the score.
They need to chop up the score in order to be able to override any genre implications I might be making.
I think my job is to pave the way for detail, beautiful detail.
For instance, Fiona Apple’s “Hot Knife.”
This song walks a dangerous line in its appeal to musical exoticism (a tricky business which I’ve written about elsewhere).
But what really makes this song interesting is the last verse/layer.
This verse enters at 2:55 on the low dominant scale degree.
This verse marks the beginning of the closest mic-ing yet.
The verse text (Maybe he could teach me something/ Maybe I could teach him too/ Even just the once goes to show you that he/ Is never gonna get a hold on you) is only partially perceptible, but her pharyngeal sounds (saliva, breath, etc) come through clearly.
And at 3:15 we get vocal intimacy in the right channel for the first time.
I am so excited about a world where the composer doesn’t make that tiny, right-channel saliva moment at 3:19.
The composer’s job is to set the scene for such an event.
The performers make it happen, and the listeners (potentially) make something of it.
I realized recently, am I after performer instinct?
I realized recently, I love voice but maybe it’s best for only the trace of an inspiration to be apparent in a work, maybe not the full weight of the inspiration itself.
I realized recently, there needs to be something they can hang their hat on.
In the midst of all this color-based interpretive work, I think my love of language should be a couple degrees removed from the surface of the score.
With that, I’ll leave you with a little of my discarded text for So, as well as the linguistic and alinguistic stylings of Reggie Watts.
[box]I’m a Grohl, I’m a Schick
I’m a Sonny, I’m a la, I’m a once
I’m a colortext
I’m a spoken voices, spoken voices
We usually talk about every third day
We usually talk about we always talk
We usually talk about God did that
But you’ll never happen, never happen[/box]
[line]
[line]
Thanks for stopping by. More to come!
[line]
[textwrap_image align=”right”]http://www.theoperatingsystem.org/wp-content/uploads/2014/03/unnamed-2.jpg[/textwrap_image]KRISTINA WARREN (b. 1989) is a composer and vocalist who holds a B.A. in Music Composition from Duke University and is currently pursuing a Ph.D. in Composition and Computer Technologies from the University of Virginia. Recent works include Three Sonnets of Elizabeth Barrett Browning (soprano, electronics), Folk Studies No. 1 (Up in the A.M.), No. 2 (Vimeda Sakla), and No. 3 (Shousty) for voice-based electronics, and Pogpo (electric guitar quartet). Warren’s research interests include voice, electronics, and questions of aleatoryand performance practice in conjunction with various non-Eurocentric musics, such as folk music and Korean p’ansori. Warren’s compositions have been performed across the US and in Europe, and she has been fortunate to study composition with Ted Coffey, Judith Shatin, Anthony Kelley, Scott Lindroth , and John Supko.
[line]
[recent_post_thumbs border=”yes”]